
DZoneのNick Pegg記者は、AIデータラベリングの品質管理手法の見直しが必要であるという記事を発表した。
従来の手法は「この画像に猫が写っているか」といった単純なタスクには適していたが、現在のマルチモーダルデータセットや文化的差異を含む主観的判断、エッジケースの文脈理解には対応できない。従来のQC手法には5つの問題がある。アノテーター間一致度の精度低下、品質管理専門家の疲労増加、固定ゴールドスタンダードの限界、サンプリング手法の不適切さ、品質測定の過度な単純化である。
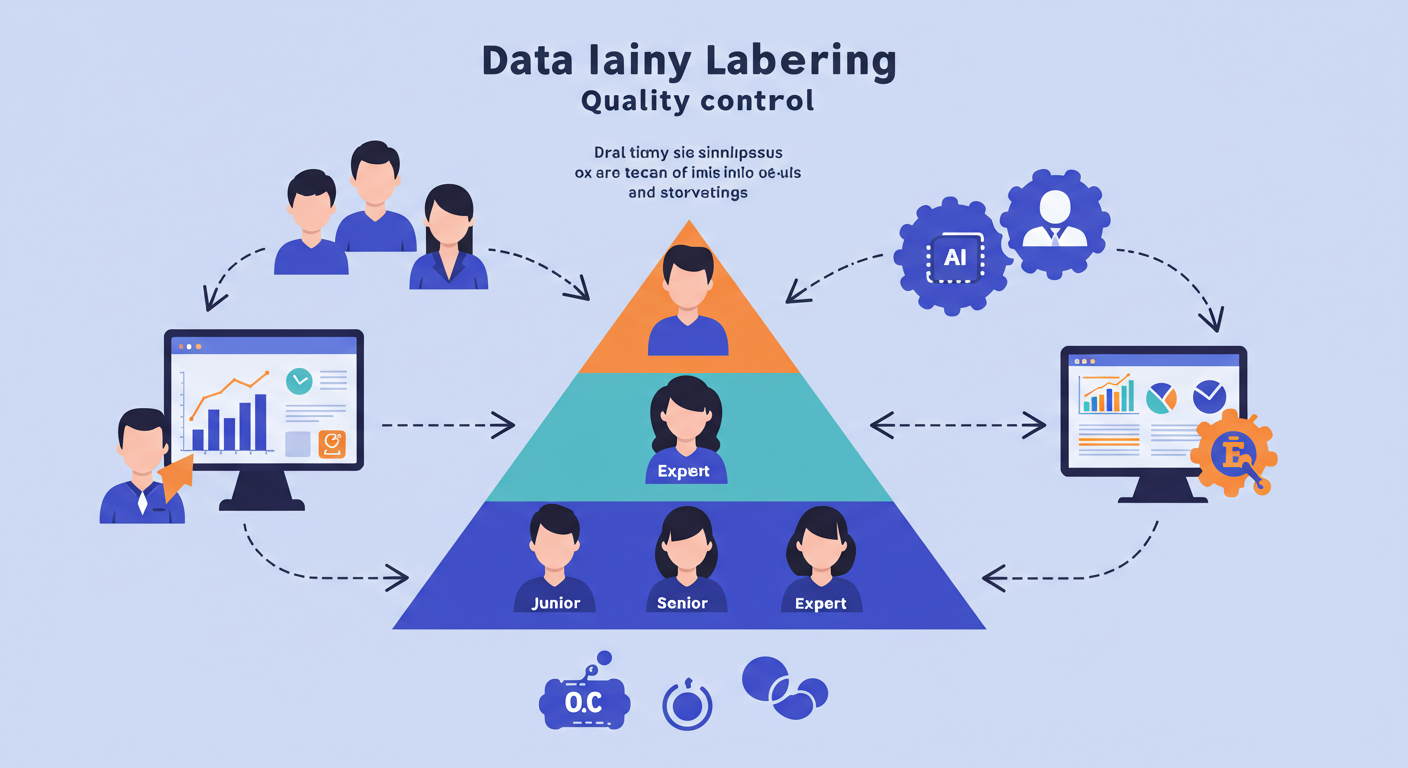
新しいアプローチとして4つの戦略を提示している。3層レビューシステムによる階層的品質チェック、意味的整合性や境界F1スコアなどタスク固有の動的指標、能動学習アルゴリズムを用いた自動化と人間レビューの組み合わせ、アノテーターの行動を継続監視する自動化リアルタイムフィードバックループである。
記事では自動運転車両など安全性重要アプリケーションで90%精度が不十分な例や、車両欠陥検出でのポリゴンアノテーション活用例を挙げている。
From:  Reevaluating Quality Control Methods in Data Labeling
Reevaluating Quality Control Methods in Data Labeling
【編集部解説】
AIデータラベリングの品質管理は、今まさに転換点を迎えています。この記事で指摘されている課題は、AI開発の現場で日々直面している現実的な問題です。
従来の品質管理手法が限界を迎えている背景には、AIタスクの複雑化があります。かつてのシンプルな画像分類や物体検出とは異なり、現在は感情分析、皮肉の検出、医療画像診断など、人間でも判断に迷うような高度なタスクが主流となっています。記事で言及された「90%の精度が自動運転車両では不十分」という例は、まさにAI時代の品質基準の厳格化を象徴しています。
特に注目すべきは、アノテーター間一致度の問題です。高い一致度が必ずしも品質を保証しないという指摘は、業界で長年見過ごされてきた盲点でした。複数の専門家が同じ間違いを犯すケースは、医療分野や法務分野でも頻繁に報告されており、単純な統計指標に頼る危険性を浮き彫りにしています。
記事で提案されている4つの新アプローチは、すでに一部の先進企業で実装が始まっています。特に「Human-in-the-Loop(HITL)」アプローチは、2025年のデータラベリング業界で最重要トレンドの一つとして注目されています。AIが不確実性の高いサンプルを特定し、人間がそこに集中的にリソースを投入する手法は、効率性と品質の両立を実現する画期的な解決策です。
ある研究では、階層的品質チェックシステムの導入により、コスト効率は60%以上改善されるという研究結果も報告されています。ジュニアレビュアーがルーチンタスクを処理し、複雑なケースのみドメインエキスパートが担当する仕組みは、人材不足に悩む業界にとって現実的な解決策といえるでしょう。
リアルタイムフィードバックループの実装は、アノテーター疲労という長年の課題に対する技術的回答です。デジタル検証により手作業と比較して最大78%のエラー削減が可能という報告もあり、人間の限界を技術で補完するアプローチの有効性が証明されています。
ただし、これらの新手法にも課題があります。実装コストの増加、技術者不足、そして何より組織の意識改革が必要です。多くの企業がレガシーシステムから脱却できずにいる現状を考えると、段階的な移行戦略が重要になります。
この品質管理革新は、AIの信頼性向上に直結します。特に医療、金融、自動運転など、ミッションクリティカルな分野でのAI普及を加速させる可能性があります。一方で、高度化する品質要求は、データラベリング業界の専門性をさらに高め、参入障壁の上昇という副作用も予想されます。
2025年以降、AI開発において「データは新しい石油」から「高品質データは新しい金」へとパラダイムが変化していくでしょう。この記事が提起する品質管理の再定義は、AI業界全体の成熟度を測る重要な指標となりそうです。
【用語解説】
データラベリング
機械学習モデルの訓練に必要な教師データを作成するため、画像や文章などのデータに正解となるタグや境界線を付ける作業。
アノテーション
データラベリングと同義。より技術的な文脈で使われる専門用語で、データに注釈や属性情報を付与すること。
アノテーター間一致度(Inter-Annotator Agreement)
複数のアノテーターが同じデータに対して行ったラベリング結果の一致度を示す指標。高いほど客観的とされてきた。
Human-in-the-Loop(HITL)
人間とAIが協力してタスクを実行するアプローチ。AIが初期処理を行い、人間が検証・修正する仕組み。
ゴールドスタンダード
機械学習において正解とみなされる高品質な参照データセット。品質評価の基準として使用される。
能動学習(Active Learning)
AIモデルが自ら学習に効果的なデータを選択し、そのデータに対する人間の判断を求める学習手法。
バウンディングボックス
画像内のオブジェクトを四角形で囲んで位置を示すアノテーション手法。物体検出でよく使用される。
ポリゴンアノテーション
複雑な形状のオブジェクトを多角形で精密に囲むアノテーション手法。より高精度な境界検出が可能。
エッジケース
AIモデルが判断に困る稀で複雑なデータパターン。従来の品質管理では見落とされやすい。
【参考リンク】
DZone(外部)
開発者向けの技術情報サイト。クラウド、AI、DevOpsなど最新の技術トレンドに関する記事を提供
SunTec.AI(外部)
AIプロジェクト向けのデータアノテーションサービスを提供する企業。車両欠陥検出事例で紹介
Labellerr(外部)
Human-in-the-Loopアプローチを活用したデータラベリングプラットフォームを提供
【参考記事】
6 Data Labeling Trends To Watch in 2025(外部)
2025年のデータラベリング業界で注目すべき6つのトレンドを解説。HITLが最重要トレンド
Quality Control in Labelling: Best Practices for 2025(外部)
デジタル検証により手作業と比較して最大78%のエラー削減が可能という数値を報告
How Human-in-the-Loop is used in Data Annotation?(外部)
HITLが15-30%の時間を追加するが、後の手直しコストを大幅削減することを説明
The Importance of Reinforcement Learning From Human Feedback(外部)
階層的品質チェックシステムにより60%以上のコスト効率改善が可能とする研究結果
Advanced Techniques in Data Labeling for Enhanced Machine Learning(外部)
機械学習モデル向上のための高度なデータラベリング技術を紹介。従来手法の限界を分析
【編集部後記】
みなさんの身の回りで活用されているAIサービスは、実は膨大なデータラベリング作業の上に成り立っています。写真の顔認識から音声アシスタント、商品レコメンデーションまで、その精度は全てデータの品質にかかっているのです。
今回の記事で紹介された品質管理の課題は、私たちが日常使うAIの性能に直結する問題でもあります。もしかすると、みなさんの職場でもAI導入プロジェクトで似たような課題に直面しているかもしれませんね。
「自分の業界でAIを活用するとしたら、どんなデータが必要だろう?」「そのデータの品質をどう担保するか?」そんな視点で身の回りを見渡してみると、新たな発見があるかもしれません。みなさんはどのようにお考えでしょうか。