
AI(人工知能)ニュース
次世代の有力な画像生成AIモデル「FLUX.1」もローカルで使ってみよう。商用利用も可能

Stable Diffusionの規制が強まる今、次世代の画像生成AIとして注目されているものの一つがFLUX.1です。FLUXはStable Diffusionと同様に、完全無料でローカルの環境で利用することができるのが特徴です。今回は、このFLUXを「ComfyUI」というUI上で利用するための手順について解説します。
FLUX.1とは?
「FLUX.1」とは、元Stable Diffusion開発チームだったメンバー数名によって立ち上げられた企業である「Black Forest Labs」が開発した新たな画像生成AIモデルです。
Stable Diffusionほどオープンなモデルではありませんが、ベースとなるモデルとウェイトは公開されているため、コミュニティによる研究開発が盛んな画像生成AIです。Stable Diffusionからののれん分けという立場から、ユーザーの流入も多く、まだ比較的歴史が浅いとは言え、すでにある程度のマージモデルなどが流通しています。
また、FLUXも同様に「拡散モデル」であり、入力されたプロンプトをもとに、ランダムなノイズ画像から画像を生成する仕組みですが、大きく異なる点として、Stable Diffusionが単語や短文と画像を結び付けて学習させる、LAIONが開発した「OpenCLIP」を使用していたのに対して、FLUXはGoogleの「T5」をベースにしたもの利用しており、画像を単語や短文のようなタグとの関連性ではなく、キャプション的な文章とリンクして学習している点です。
そのため、こちらがAIにわかりやすいような単語をプロンプトとして入力する必要があったのに対し、私たちの普段の言葉遣いを理解しやすくなっています。加えて、以前のような単語ベースのプロンプトもしっかりと効くようになっています。こちらのほうが、生成処理の段階で、文章がテキストエンコーダーを通じ、最終的なプロンプトとして調整される段階で情報が失われることが少ないため、重要な要素は変わらず単語ごとに入力するといった使い分けが重要になります。
目次
はじめに
FLUXはStable Diffusionで最もメジャーなUIとして知られる「AUTOMATIC1111」に対応していません。
「WebUI Forge」という、AUTOMATIC1111から派生し、より軽量に使いやすくというコンセプトで開発されたUIに対応しています。こちらのほうがStable Diffusionに馴染みのある人には移行しやすいかもしれませんが、今回はあえて「ComfyUI」という風変わりなUIでの利用方法について解説していきます。
というのも、後ほど詳しく解説しますが、ComfyUIのほうが自由度が高いからです。比較的低コストで、オープンな部分が多かったStable Diffusionよりも、FLUXのような後出のややハイスペックで複雑なモデルを運用するには、ComfyUIが最も適していると言えます。
その分導入手順や、使い方も複雑にはなってしまいますが、ここは使ううちにすぐ慣れると思います。これも、その理由について詳しいことは後ほど解説します。
そして、ローカルで利用できるFLUXには「Schnell(シュネル)」と「Dev(デヴ)」という二つのモデルが存在します。
それぞれの特徴をまとめると以下のようになります。
| Schnell | Dev |
|---|---|
| 高速・軽量モデル | 高品質・開発者向けモデル |
| 商用利用が可能 | 商用利用は原則不可 |
| SD3.5より低クオリティ | SD3.5より高クオリティ |
SchnellはApache2.0ライセンスの元、商用利用が可能となっています。
Devの商用利用の原則禁止とは、Devの学習モデル、およびその派生モデル自体を商用利用することを禁止するものであり、生成した画像の商用利用は可能です。これは2024年8月にライセンスが変更され、2025年6月に現在の文面に整えられたことで明言されたライセンスのため、「一切の商用利用ができない」というのは過去の情報になります。
ただ、注意すべき点としては、顧客から「こういう画像を作ってほしい」という依頼に対して、Devモデルを使用して生成した画像を納品することは「モデル自体の商用利用」とみなされる可能性がありますので、詳しくは公式ライセンスや、弁護士など専門家の意見を確認してください。
FLUX.1-dev非商用ライセンス|HuggingFace(外部サイト)
以下はローカルでFLUXを利用するために必要なパソコンスペックの目安になります。FLUXには先述の通り、規模の違うモデルがあり、更に「量子化」というさらなる軽量モデルもあるので、一概にこれだけあれば絶対十分!というラインはないということを念頭に入れておいていただきたいです。
最低環境(ギリギリ動かせる)
| OS | Windows10 64bit |
| GPU | NVIDIA GeForce RTX 4060 (VRAM 8GB) |
| 容量 | 30GB以上の空き SSD推奨 |
| CPU | Intel Core i5 第8世代 AMD Ryzen 5 2600 |
| メモリ | 16GB |
推奨環境(快適に利用できる)
| OS | Windows10 64bit |
| GPU | NVIDIA GeForce RTX 4090 (VRAM 24GB) |
| 容量 | 100GB以上の空き SSD推奨 |
| CPU | Intel Core i9 第13世代 AMD Ryzen 9 7900X |
| メモリ | 64GB |
上の表はあくまで目安です。設定の最適化や、モデルなどによって必要なスペックは大きく変わります。最も重要なのは「NVIDIAのCUDA対応のGPUが搭載されていること」と「SSD」と「十分なメモリ」になります。FLUXはテキストエンコーダーの処理がStable Diffusionよりも複雑になるため、必要なメモリ領域がその分増えています。
導入方法
今回は「Stability Matrix」から「ComfyUI」をダウンロードする方法を紹介します。直接ComfyUIのみの環境を構築することもできますが、Stability Matrixがあれば、今後Stable DiffusionやHiDreamといった他の画像生成AIが使いたくなった時、Stability Matrixならモデルなどが一括管理でき、使いまわせるので容量の節約にもなりますし、AUTOMATIC1111やForgeといったUIのインストールも簡単にできますし、初めての人にはややこしいPythonやgitのインストールといったことも簡単にできるのでおすすめです。
デメリットとしては、各UIの更新が反映されるまでのタイムラグがあることですが、どうしても最新をその日のうちに絶対試したくて仕方がない!という人や、Pythonをバリバリ使って自分だけの環境を構築したい上級者でもなければStability Matrixを使いましょう。
Stability Matrixのインストール方法は過去の記事で紹介していますので、詳しくはそちらもご確認ください。
まずはGitHubからStability Matrixをダウンロードし、展開しましょう。そしてインストールするUI一覧の中からComfyUIを選択してインストールします。
Stability Matrix | GitHub(外部サイト)
すでにStability Matrixをインストールしている人はパッケージから「追加」を選択して、インストールします。
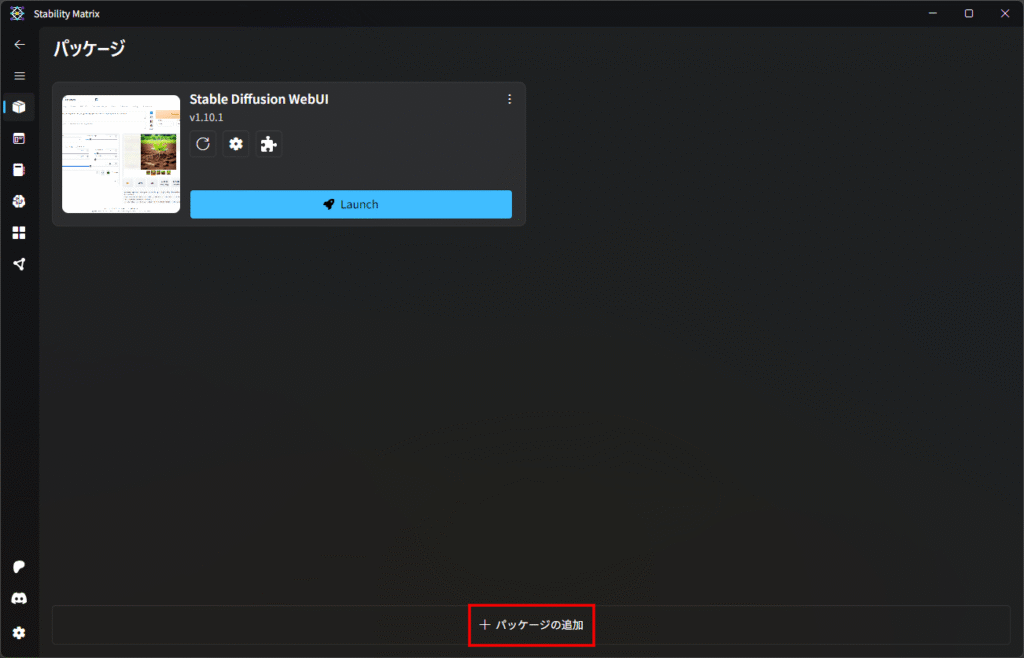
インストールが完了したら、パッケージの一覧に表示されます。次は「ComfyUI Manager」をインストールします。すぐに必要というわけではありませんが、使い込んでいくにはほぼ必須なので最初にインストールしてしまいましょう。
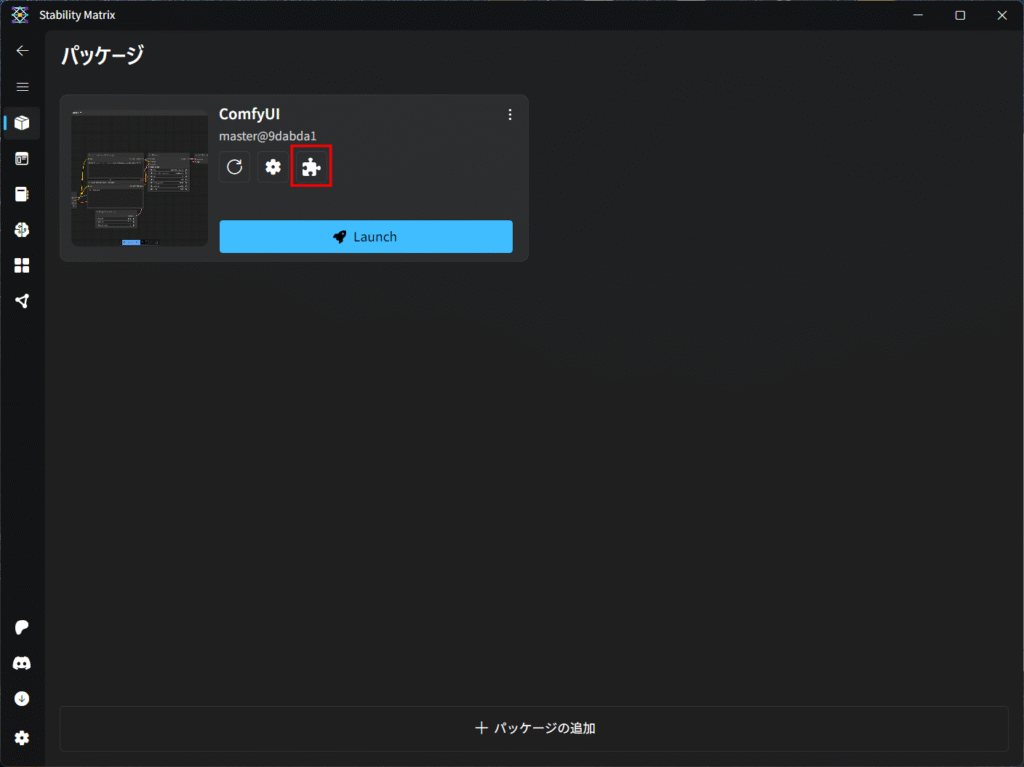
パッケージ一覧のComfyUIのカードにあるパズルのピースのようなアイコンをクリックします。
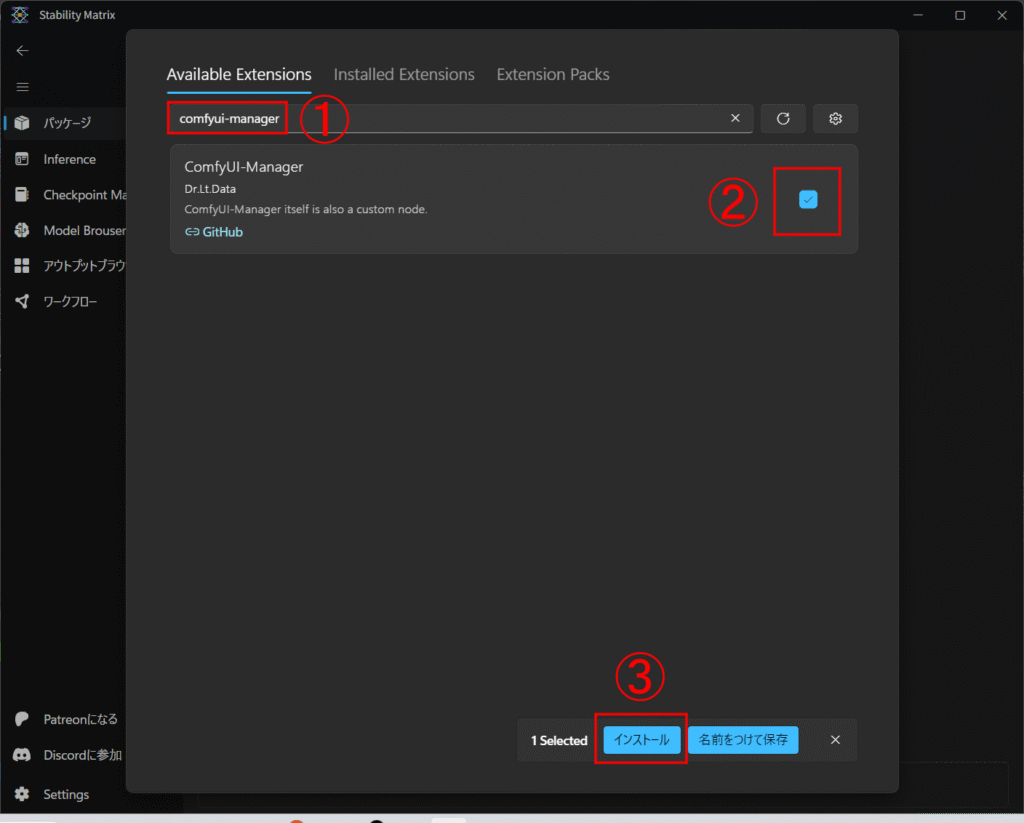
そうしたら「ComfyUI-manager」で検索し、出てきたものにチェックを入れてインストールします。
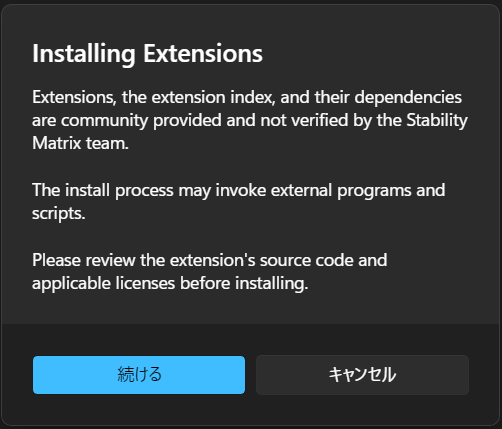
そうすると警告が出てきます。ComfyUI Managerなどの拡張機能は様々なユーザーがつくったものが公開されていて、Stability Matrixはそれらをダウンロードするのを補助するためのマネージャーアプリにすぎません。なので、中にはウイルスなどが仕組まれている可能性があります。それについてStability Matrixは責任を取りません。といった警告です。今回はそのまま続けて問題ありません。
インストールが完了したら、ComfyUIを開いてみましょう。パッケージ一覧から「Launch」をクリックして起動させます。
ズラズラとログが出てきて、しばらくすると上に「Web UIを開く」ボタンが表示されますので、これをクリックするとブラウザでComfyUIが起動します。
画面右上に青色の「Manager」ボタンがあれば、ComfyUI Managerのインストールも完了しています。
最初は何もないマス目の画面だけが表示されていると思いますが、ここがワークスペースになり、ここに様々なノードを配置し、それらをつなぎ合わせていくのがComfyUIの使い方になります。
それでは、まずモデルとテキストエンコーダーをダウンロードしましょう。
FLUX.1-schnell|Hugging Face(外部サイト)
FLUX.1-dev|Hugging Face(外部サイト)
公式モデルのダウンロードにはHuggingFaceのアカウントと、利用規約への同意が必要となります。
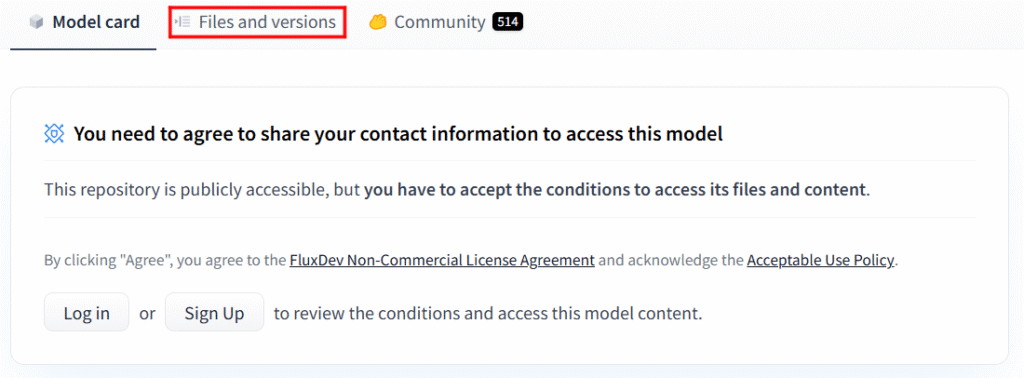
このような通知が出てきますので、ログインした状態で利用規約に同意した後、「Files and versions」タブをクリックします。
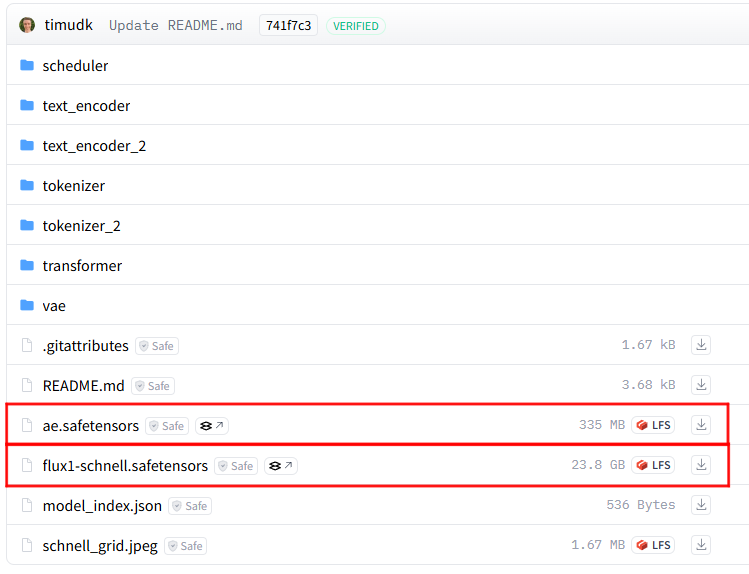
「ae.safetensors」と「flux1-schnell(dev).safetensors」を一番右側のアイコンをクリックしてダウンロードします。
「ae.safetensors」はVAEと呼ばれるもので、簡単に説明すると、拡散モデルの画像生成AIにおいて、生成の最後に画像を整えるために必要なファイルです。モデルによってはVAEが最初からモデルのほうに組み込まれていて不要なこともありますが、今回ダウンロードする公式のモデルには別添えで必要なものになります。
VAEの保存先
StabilityMatrix-win-x64\Data\Models\VAE
モデルデータの保存先
StabilityMatrix-win-x64\Data\Models\DiffusionModels
次はテキストエンコーダーをダウンロードしましょう。
FLUX-Text-Encoder|Hugging Face(外部サイト)
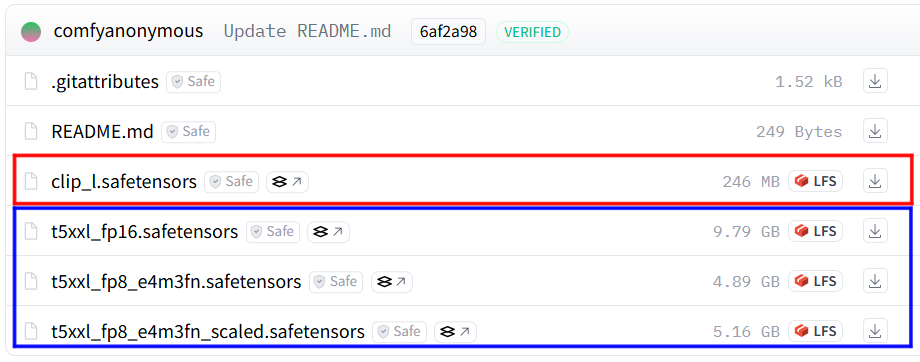
まずは「clip_l.safetensors」が必須で、青枠の中の「t5xxl」はどれか一つがあれば十分です。
何が違うのか?と言われると、性能が違います。fp16>>fp8 scaled>fp8となっており、fp16が最も高性能ですが、その分処理の負荷が大きくなります。念のためすべてダウンロードして、いろいろ試してみるのがいいと思います。
テキストエンコーダーの保存先
StabilityMatrix-win-x64\Data\Models\TextEncoders
これで画像生成に必要最低限のものはそろいましたので、次はComfyUIに移って画像を生成してみましょう。
利用方法
さぁ、画像生成をしましょう。といっても、ComfyUIにはまだ何もないと思います。なので、ComfyUIの開発者がGitHubでFLUXの使用例を紹介しています。英語ではありますが、ブラウザの翻訳機能を使えば十分理解できる内容だと思います。
また、このページには「FP8」という軽量モデルも紹介されています。schnellでも重くて使い勝手が悪い、と思ったら試してみるのもいいかもしれませんが、当然生成画像のクオリティも下がりますのでご注意ください。
まずはschnellを例として説明します。
上記リンク先のページで、上から2番目の「Flux Schnell」見出しの下にある、鮮やかな瓶の画像をComfyUI上にドラッグしてみましょう。(画像を保存する必要はありません。)
すると、以下のようなものが表示されるかと思います。この線でつながったカードがノード(カスタムノード)と言われるものです。
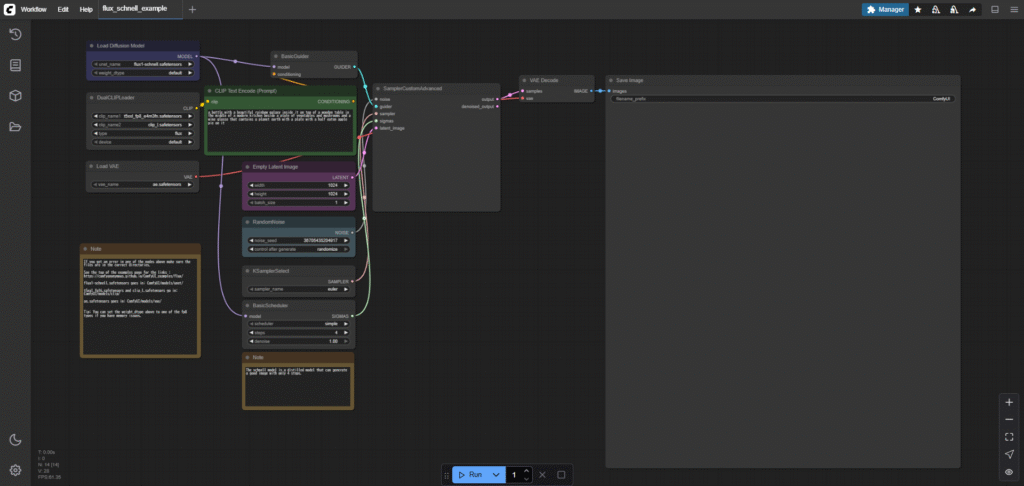
もしなにか足りないデータがあると表示が出ます。GitHubやHuggingFaceで入手できるものなら、ここでまとめてダウンロードすることもできます。
このまま、下の「Run(実行)」ボタンを押せばサンプルと同じ画像が生成されます。
このように、ComfyUIで生成した画像は、その情報がメタデータとして画像に保存されるため、ほかの人が生成した画像で気に入ったものがあれば、どのようなフローになっているのか、どのようなプロンプトを用いているのかがわかるようになっています。(もちろん消されていたら見れませんが…)
このため、ComfyUIは難しそうに見えても、生成画像のプロセスを見ることができるので、いろいろ見ていくうちに自然と身につくものが多いでしょう。
今回はサンプル画像なので、ノードやフロー自体も至ってシンプルです。AUTOMATIC1111などを利用したことがある人は見覚えのあるような内容になってるかと思います。
それぞれのノードを一つずつ解説します。
「Load Diffusion Model」
読み込む拡散モデル(学習モデル)を選択します。
「DualCLIPLoader」
FLUXはStable DiffusionのようなCLIPとT5の二つを利用してプロンプトを処理しているため、Dualである必要があります。
「Load VAE」
読み込むVAEを選択します。
「CLIP Text Encode(Prompt)」
プロンプトを入力するところです、プロンプトは「, 」(半角カンマと半角スペース)で区切ることで区別させます。
「Empty Latent Image」
生成する画像のサイズを指定します。数字は8の倍数である必要があります。
「Batch_size」は一度に何枚同時に生成するかの設定です。大きくすれば当然パソコンにかかる負担が大きくなります。
「RandomNoise」
毎回ランダムな画像を生成するためのシード値の設定ができます。「control after generate」によって、画像を生成した後にシード値を「固定する(fixed)」「1増やす(increment)」「1減らす(decrement)」「ランダムに変える(randomize)」から選べます。
「KSamplerSelect」
画像からどうやってノイズを除去していくのか指定できます。よくわからなかったら「euler_ancestral」がおすすめです。
「BasicScheduler」
ノイズ除去をどういうペースで行うのかを指定できます。よくわからなかったら「karras」がおすすめです。
「steps」は何回ノイズ除去をするかの設定です。多ければ多いほどきれいな画像になる傾向ではありますが、最大でも25程度やれば、以降はほとんど違いは出ません。schnellはこれが4で済むというのが売りです。
「denoise」は画像から何%ノイズを取り除くかという指定です。例えば、0.7にすると、プロセスのうち、最初の30%は何もせず、後半70%はノイズを取り除いていくことになります。プロンプトから画像を生成するText-to-Image(T2I)ならほぼ必ず1.0、すでにある画像から新たな画像を生成するImage-to-Image(I2I)なら調整する必要があります。
「BasicGuider」
モデルとコンディショニング(テキストエンコーダーを通したプロンプト)を受け取り、画像の設計図(Guider)を渡すような処理が行われます。
「SamplerCustomAdvanced」
上記のGuiderと、様々な処理を受け取り、潜在画像という、人間が見ても意味不明な、圧縮された画像を生成する処理が行われます。
「VAE Decode」
最後に潜在画像を視覚的な情報を持った画像へと復元する処理が行われます。
「Save Image」
出来上がった画像が表示されます。
ComfyUIの自由度とは、この細かいプロセスの一つ一つを設定することが容易だということです。ComfyUIに最初から備わっているノードだけでなく、ComfyUI Managerによってユーザーが作成した様々なノードをダウンロードして組み合わせていけば、より詳細に生成される画像をコントロールすることができます。
使いこなせれば、画像だけでなく、動画や音声、3Dモデルなども生成できますし、学習などもこなせます。
ノードを追加するには、ワークスペース上で右クリックして「Add Node」を選択するか、左側バーの上から2番目のアイコンから「NODE LIBRARY」から検索するかの方法があります。線はドラッグアンドドロップで引くことができます。
たとえば、このサンプルを少し改造して、少しさっぱりさせつつ、ネガティブプロンプトを入力できるようにしてみましょう。
※基本的にノードの接続する点は、左側にあるのが入力で、小文字で書かれており、右側にあるのが出力で、大文字で書かれています。
1.「BasicGuider」と「RandomNoise」と「KsamplerSelect」と「BasicScheduler」と「SamplerCustomAdvanced」を削除してしましましょう。ノードをクリックするとその真上に赤いゴミ箱マークが出るのでこれをクリックして削除します。
2.ノードを追加します。右クリック、Add Node→sampling→「KSampler」を追加します。NODE LIBRARYならそのまま「Ksampler」で検索すれば一番上に出てきます。
3.Add Node→conditioning→「CLIP Text Encode(prompt)」を追加します。すでにあるものをコピーしてもいいです。
4.「Load Diffusion Model」の右上「MODEL」というところから、「Ksampler」の左上「model」まで線を引きます。
5.「DualCLIPLoader」の「CLIP」から新しく追加した方の「CLIP Text Encode(prompt)」の「clip」につなぎます。
6.二つの「CLIP Text Encode(prompt)」の「CONDITONING」から、「KSampler」の「positive」「negative」につなぎます。
7.「Empty Latent Image」から「VAE Decode」につながっていると思いますが、これを「KSampler」の「latent_image」につなぎます。線を消したいときは線の真ん中にある丸をクリックして「Delete」を選択すれば接続を切ることができます。
8.最後に「KSampler」の「LATENT」から「VAE Decode」の「samples」に接続します。
9.あとは設定を微調整しましょう。「KSampler」の「steps」を4に「cfg」を1.0に変更しました。「Save Image」の表示も少し小さくしておきましょう。
これで実行すれば画像が生成されます。ノードを切り貼りして設定が少し変わっているのでサンプル画像に似た別の画像が生成されるはずです。
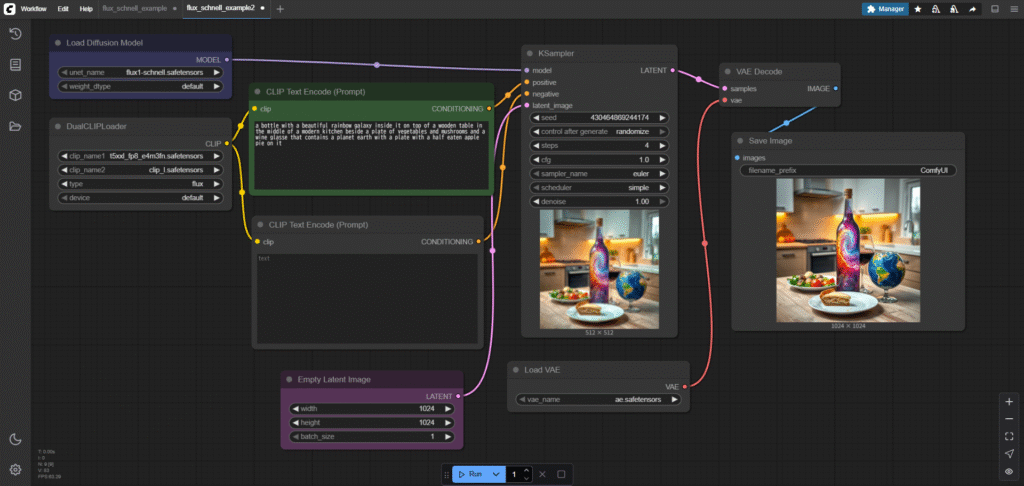
このように、画像を生成するのに決まった方法というのはありません。いろいろな試行錯誤が思わぬ結果をもたらすことでしょう。
ちなみに、Stable Diffusionになじんだ人だとcfgが1.0でいいということに驚くかもしれません。FLUXがもともとプロンプトへの追従性が高くつくられているため、それに対してcfgをいつもの感覚で7.0ぐらいにすると、過剰なまでにプロンプトに引きずられて色彩が狂ったり破綻したりしてしまいます。
また、schnellのような軽量化が施された蒸留モデルはstepsを上げてもクオリティの上昇には貢献しにくいです。少ない数字にしておいた方がタイムパフォーマンスがよくなりがちです。
ネガティブプロンプトもStable Diffusionほどは必要なく、よっぽど気になる要素があれば明記して除く程度で十分でしょう。
また、FLUXもLoRAを使用することができます。使いたい場合はAdd Node→loaders→「Load Lora」で追加し、「Load Diffusion Model」と「KSampler」の間、「DualCLIPLoader」と「CLIP Text Encode」の間になるようにつなぐだけです。
ただ、当然ですが、学習モデルの構造が全く違うため、Stable DiffusionとFLUXのLoRAはまったく互換性がありませんので注意しましょう。
構築したワークフローは左上の「Workflow」から「Save As」で保存することができます。
タブでいくつもワークフローを同時に開くこともできるので、用途に合わせた設定をそれぞれ保存しておくことをおすすめします。
以上がComfyUIの基本的な使い方になります。
よくある症状と対処方法
ComfyUIが起動しない
Stability Matrix側のログに「error while attempting to bind on address (‘127.0.0.1’, 8188): 通常、各ソケット アドレスに対してプロトコル、ネットワーク アドレス、またはポートのどれか 1 つのみを使用できます。」と出ていませんか?これは8188のポートが何かに使われていて、使用できなかった時に表示されるエラーです。大半は、閉じたつもりのComfyUIがまだ動き続けてしまっていることが原因です。
コマンドプロンプトを起動し、
netstat -ano | findstr :8188
と入力してみてください。(ポート番号は人によって違う場合がありますので、エラーログをよく確認しましょう)
そうすると、該当のポート番号が何に使われているかが出てきます。
(例)TCP 127.0.0.1:8188 0.0.0.0:0 LISTENING 12345
そうしたら、コマンドプロンプトで以下のコマンドを実行し、ポートを使用しているプログラムを強制的に終了させます。
taskkill /PID 12345 /F
これで改善します。
ComfyUIが動かなくなった
Stability Matrixのほうを確認してみましょう。こちらでComfyUIが止まってしまっていることがたまにあります。その場合は起動しなおしてみましょう。
インストールしたモデルが見つからない
起動中にインストールしたものを表示するにはブラウザを更新をする必要があります。この更新でStability Matrix上でComfyUIが止まってしまう可能性もあるので、併せて確認しましょう。
最後に
今回は「ComfyUI」を使って「FLUX.1」をローカルで運用する方法を紹介してきました。
画像生成に関する大まかな知識はStable Diffusionと共通するものが多いので、ぜひ過去の使い方ガイドも確認していただければ今回の記事で説明しきれなかったことも理解できるかもしれません。
FLUXも「Civitai」に多くのモデル(checkpoint)やLoRAが公開されています。schnellとdevの違いに気を付けながら、ライセンス等をしっかり確認したうえで利用しましょう。
また、なかにはNF4やGGUFといった「量子化」と呼ばれるモデルも存在します。容量も少なく、GPUへの負担も少ないのがメリットですが、やはりもともとのモデルの情報量はどうしても減ってしまうので、クオリティが落ちたり、LoRAの互換性が下がるなどのデメリットも相応にあります。
量子化モデルにはq8やq2といったq+数字がモデルの名前についていることがあります。これは数字が小さいほど軽量化されているということを表しています。
お手持ちのパソコンのスペックや、これから購入する際にはぜひ参考にしてみてはいかがでしょうか。
AIによる画像生成は意図せず第三者の著作権・肖像権・商標権などを侵害するリスクもあります。また、モデルデータや追加学習データによっては商用利用を禁止していたり、商用利用以外でも公開の際にクレジット表記が求められる場合もありますので、公開・商用利用の際は、各モデルの利用規約や関連する法律を必ず確認してください。
【関連記事】






ウェールズの研究者が、ジャガイモ疫病と戦うためのAIアプリ「DeepDetectプロジェクト」を開発している。
ジャガイモ疫病は世界のジャガイモ作物の約20%の損失を引き起こし、総額45億ドル以上の経済的損失をもたらしている。この病気はPhytophthora infestans(フィトフトラ・インフェスタンス)という病原体によって引き起こされる。
従来の検査は労働集約的で費用がかかり、ヒューマンエラーが発生しやすいため、見逃された場合は病気が畑全体に広がる可能性がある。新しいAIアプリはスマートフォンのカメラを使用してジャガイモの葉の変化を検出し、農家が通常現れる前に病気の兆候を察知できるようにする。
ウェールズでは17,000ヘクタール以上がジャガイモ栽培に充てられているとされる。研究者は農家からの直接的なフィードバックを収集中で、早期診断により農家がより迅速に病気と戦えるようになることを期待している。この技術は将来的にジャガイモを超えて農業産業の他分野にも拡張される可能性がある。
From: ![]() Researchers Want To Use AI To Fight Potato Blight
Researchers Want To Use AI To Fight Potato Blight
【編集部解説】
このニュースが注目すべき理由は、農業分野におけるAI活用の新たな地平を示している点にあります。特に食料安全保障の観点から、ジャガイモ疫病という世界的な課題に対する革新的なアプローチが提示されています。
従来の農業では、病気の検出は人間の目視に頼る部分が大きく、症状が目に見えるようになった時点では既に手遅れになることが多々ありました。Phytophthora infestans(フィトフトラ・インフェスタンス)という病原体によるジャガイモ疫病は、1845年のアイルランド大飢饉の原因ともなった歴史的な脅威であり、現在でも湿度の高い条件下では数週間で作物を全滅させる可能性があります。
アベリストウィス大学のDeepDetectプロジェクトは、コンピュータビジョンと機械学習を組み合わせて、スマートフォンのカメラを通じてジャガイモの葉の微細な変化を検出し、人間の目では見えない初期段階での病気の兆候を捉えることを目指しています。この技術の革新性は、従来の広域予防散布からtargeted intervention(標的介入)へのパラダイムシフトにあります。
ある報告によると、ウェールズの農家は予防的な殺菌剤散布に年間500万ポンド以上を費やしていると推定されています。このAIシステムが実現すれば、必要な場所にのみピンポイントで対策を講じることが可能になり、大幅なコスト削減と環境負荷軽減が期待できます。
技術面では、このシステムがリアルタイム位置情報と組み合わされることで、location-specific disease diagnoses(場所特有の病気診断)を提供できる点が重要です。これにより、農家は自分の畑の特定の区画に対して即座に対応できるようになります。
興味深いのは、開発チームが最初から農家との共同設計アプローチを採用していることです。これにより、技術的に優れていても実用性に欠けるという、多くの農業技術製品が陥りがちな問題を回避しようとしています。
将来的な展望として、この技術は他の作物や病害にも応用可能とされており、農業分野におけるpredictive analytics(予測分析)の基盤技術となる可能性があります。特に気候変動により病害の発生パターンが変化する中で、このような早期警告システムの重要性はますます高まるでしょう。
一方で、農家のデジタルリテラシーや通信インフラの整備状況、データプライバシーの問題など、実装に向けた課題も存在します。また、AIの判断精度やfalse positive(偽陽性)・false negative(偽陰性)のリスクについても、実用化に向けて慎重な検証が必要です。
この研究はウェールズ政府のSmart Flexible Innovation Support(SFIS)プログラムの支援を受けており、政府レベルでも農業のデジタル変革が重要政策として位置づけられていることがわかります。世界人口の増加と気候変動という二重の課題に直面する現代において、このような技術革新は単なる効率化を超えた、人類の生存戦略としての意味を持っています。
【用語解説】
potato blight(ジャガイモ疫病)
Phytophthora infestansという病原体によって引き起こされるジャガイモの致命的な病気である。感染した植物から数日で広大な畑を全滅させる能力を持ち、1845年のアイルランド大飢饉の原因ともなった歴史的な脅威である。
machine learning(機械学習)
データから自動的にパターンを学習し、予測や分類を行うAI技術である。農業分野では作物の病気検出や収穫量予測などに活用されている。
targeted intervention(標的介入)
特定の問題が発生している場所にのみピンポイントで対策を講じるアプローチである。従来の広域予防散布と対比される効率的な手法である。
【参考リンク】
Aberystwyth University(アベリストウィス大学)(外部)
ウェールズにある公立大学で、今回のDeepDetectプロジェクトを主導している。農業科学や環境科学の分野で高い評価を受けている。
Welsh Government(ウェールズ政府)(外部)
イギリスの構成国の一つであるウェールズの地方政府。Smart Flexible Innovation Supportプログラムを通じて農業技術革新を支援している。
【参考動画】
【参考記事】
Farming’s new weapon: AI app to spot potato blight before it hits(外部)
ウェールズの科学者が開発中のDeepDetectプロジェクトについて詳しく報じた記事。予防散布に年間527万ポンドを費やしているウェールズの現状や具体的な情報を提供している。
Potato blight warning app to use AI to help farmers – BBC News(外部)
BBCによるDeepDetectプロジェクトの報道。ジャガイモが世界で4番目に重要な主食作物であることや食料安全保障の観点からこの技術の重要性を説明している。
Agriculture Technology News 2025: New Tech & AI Advances(外部)
2025年の農業技術トレンドについて包括的に分析した記事。世界の農場の60%以上がAI駆動の精密農業技術を採用すると予測している。
Phytophthora infestans: An Overview of Methods and Attempts(外部)
Phytophthora infestansの科学的研究論文。病原体の遺伝子構造や高い変異率について詳細な説明を提供している。
【編集部後記】
農業とAIの融合は、私たちの食卓の未来を大きく変える可能性を秘めています。スマートフォンひとつで作物の病気を早期発見できる時代が目前に迫っている今、皆さんはどんな農業の未来を想像されますか?
食料安全保障という人類共通の課題に対して、テクノロジーがどこまで貢献できるのか、一緒に考えてみませんか?また、このような技術が実用化された際、消費者である私たちの生活にはどのような変化が訪れると思われますか?ぜひSNSで皆さんの率直なご意見をお聞かせください。

法執行技術企業Axon社が開発したAIソフトウェア「Draft One(ドラフト・ワン)」が全米の警察署で導入されている。
このツールは警察官のボディカメラの音声認識を基に報告書を自動作成するもので、Axon社の最も急成長している製品の一つである。コロラド州フォートコリンズでは報告書作成時間が従来の1時間から約10分に短縮された。Axon社は作成時間を70%削減できると主張している。
一方で市民権団体や法律専門家は懸念を表明しており、ACLU(米国市民自由連合)は警察機関にこの技術から距離を置くよう求めている。ワシントン州のある検察庁はAI入力を受けた警察報告書の受け入れを拒否し、ユタ州はAI関与時の開示義務を法制化した。元のAI草稿が保存されないため透明性や正確性の検証が困難になるという指摘もある。
From: ![]() Cops Are Using AI To Help Them Write Up Reports Faster
Cops Are Using AI To Help Them Write Up Reports Faster
【編集部解説】
このニュースで紹介されているAxon社のDraft Oneは、単なる効率化ツールを超えた重要な議論を巻き起こしています。
まず技術的な側面を整理しておきましょう。Draft Oneは、警察官のボディカメラ映像から音声を抽出し、OpenAIのChatGPTをベースにした生成AIが報告書の下書きを作成するシステムです。Axon社によると、警察官は勤務時間の最大40%を報告書作成に費やしており、この技術により70%の時間を削減できると主張しています。
しかし、実際の効果については異なる報告が出ています。アンカレッジ警察署で2024年に実施された3ヶ月間の試験運用では、期待されたほどの大幅な時間短縮効果は確認されませんでした。同警察署のジーナ・ブリントン副署長は「警察官に大幅な時間短縮をもたらすことを期待していたが、そうした効果は見られなかった」と述べています。審査に要する時間が、報告書生成で節約される時間を相殺してしまうためです。
このケースは単独のものではありません。2024年にJournal of Experimental Criminologyに発表された学術研究でも、Draft Oneを含むAI支援報告書作成システムが実際の時間短縮効果を示さなかったという結果が報告されています。これらの事実は、Axon社の主張と実際の効果に重要な乖離があることを示しています。
最も重要な問題は透明性の欠如です。Draft Oneは、意図的に元のAI生成草案を保存しない設計になっています。この設計により、最終的な報告書のどの部分がAIによって生成され、どの部分が警察官によって編集されたかを判別することが不可能になっています。
この透明性の問題に対応するため、カリフォルニア州議会では現在、ジェシー・アレギン州上院議員(民主党、バークレー選出)が提出したSB 524法案を審議中です。この法案は、AI使用時の開示義務と元草案の保存を義務付けるもので、現在のDraft Oneの設計では対応できません。
法的影響も深刻です。ワシントン州キング郡の検察庁は既にAI支援で作成された報告書の受け入れを拒否する方針を表明しており、Electronic Frontier Foundation(EFF)の調査では、一部の警察署ではAI使用の開示すら行わず、Draft Oneで作成された報告書を特定することができないケースも確認されています。
技術的課題として、音声認識の精度問題があります。方言やアクセント、非言語的コミュニケーション(うなずきなど)が正確に反映されない可能性があり、これらの誤認識が重大な法的結果を招く可能性があります。ブリントン副署長も「警察官が見たが口に出さなかったことは、ボディカメラが認識できない」という問題を指摘しています。
一方で、人手不足に悩む警察組織にとっては魅力的なソリューションです。国際警察署長協会(IACP)の2024年調査では、全米の警察機関が認可定員の平均約91%で運営されており、約10%の人員不足状況にあることが報告されています。効率化への需要は確実に存在します。
しかし、ACLU(米国市民自由連合)が指摘するように、警察報告書の手書き作成プロセスには重要な意味があります。警察官が自らの行動を文字にする過程で、法的権限の限界を再認識し、上司による監督も可能になるという側面です。AI化により、この重要な内省プロセスが失われる懸念があります。
長期的な視点では、この技術は刑事司法制度の根幹に関わる変化をもたらす可能性があります。現在は軽微な事件での試験運用に留まっているケースが多いものの、技術の成熟と普及により、重大事件でも使用されるようになれば、司法制度全体への影響は計り知れません。
【用語解説】
Draft One(ドラフト・ワン):
Axon社が開発したAI技術を使った警察報告書作成支援ソフトウェア。警察官のボディカメラの音声を自動認識し、OpenAIのChatGPTベースの生成AIが報告書の下書きを数秒で作成する。警察官は下書きを確認・編集してから正式に提出する仕組みである。
ACLU(American Civil Liberties Union、米国市民自由連合):
1920年に設立されたアメリカの市民権擁護団体。憲法修正第1条で保障された言論の自由、報道の自由、集会の自由などの市民的自由を守る活動を行っている。現在のDraft Oneに関する問題について警告を発している。
Electronic Frontier Foundation(EFF):
デジタル時代における市民の権利を守るために1990年に設立された非営利団体。プライバシー、言論の自由、イノベーションを擁護する活動を行っている。Draft Oneの透明性問題について調査・批判を行っている。
IACP(International Association of Chiefs of Police、国際警察署長協会):
1893年に設立された世界最大の警察指導者組織。法執行機関の専門性向上と公共安全の改善を目的として活動している。全米の警察人員不足に関する調査を実施している。
【参考リンク】
Axon公式サイト(外部)
Draft Oneの開発・販売元でProtect Lifeをミッションに掲げる法執行技術企業
Draft One製品ページ(外部)
生成AIとボディカメラ音声で数秒で報告書草稿を作成するシステムの詳細
ACLU公式見解(外部)
AI生成警察報告書の透明性とバイアスの懸念について詳細に説明した白書
EFF調査記事(外部)
Draft Oneが透明性を阻害するよう設計されている問題を詳細に分析
国際警察署長協会(外部)
全米警察機関の人員不足状況と採用・定着に関する2024年調査結果を公開
【参考記事】
アンカレッジ警察のAI報告書検証 – EFF(外部)
3ヶ月試験運用で期待された時間短縮効果が確認されなかった結果を詳述
AI報告書作成の効果検証論文 – Springer(外部)
Journal of Experimental CriminologyでAI支援システムの時間短縮効果を否定
警察署でのAI活用状況 – CNN(外部)
コロラド州フォートコリンズでの事例とAxon社の70%時間短縮主張を報告
全米警察人員不足調査 – IACP(外部)
1,158機関が回答し平均91%の充足率で約10%の人員不足状況を報告
カリフォルニア州AI開示法案 – California Globe(外部)
SB 524法案でAI使用時の開示義務と元草稿保存を義務付ける内容を詳述
ACLU白書について – Engadget(外部)
フレズノ警察署での軽犯罪報告書限定の試験運用について報告
アンカレッジ警察の導入見送り – Alaska Public Media(外部)
副署長による音声のみ依存で視覚的情報が欠落する問題の具体的説明
【編集部後記】
このDraft Oneの事例は、私たちの身近にある「効率化」という言葉の裏に隠れた重要な問題を浮き彫りにしています。特に注目すべきは、Axon社が主張する効果と実際の現場での検証結果に乖離があることです。
日本でも警察のDX化が進む中、同様の技術導入は時間の問題かもしれません。皆さんは、自分が関わる可能性のある法的手続きで、AIが作成した書類をどこまで信頼できるでしょうか。また、効率性と透明性のバランスをどう取るべきだと思いますか。
アンカレッジ警察署の事例のように、実際に試してみなければ分からない課題もあります。ぜひSNSで、この技術に対する率直なご意見をお聞かせください。私たちも読者の皆さんと一緒に、テクノロジーが人間社会に与える影響について考え続けていきたいと思います。

2025年8月12日、AnthropicはClaude Sonnet 4が1リクエストで最大100万トークンを処理可能になったと発表した。
Public BetaとしてAnthropicのAPIとAmazon Bedrockで提供し、Google CloudのVertex AI対応は予定中である。75,000行超のコードベース解析が可能となり、内部テスト「needle in a haystack」で100%の正確性を達成した。
価格は入力200Kトークン以下が$3/M、出力が$15/M、超過分は入力$6/M、出力$22.5/Mとなる。Menlo Venturesの調査ではAIコード生成市場でAnthropicは42%、OpenAIは21%のシェアを持つ。主要顧客はCursorとGitHub Copilotで、年間収益ランレート50億ドルのうち約12億ドルを占める。初期利用はTier 4やカスタムレート制限のAPI顧客、Fortune 500企業などである。
From: ![]() Claude can now process entire software projects in single request, Anthropic says
Claude can now process entire software projects in single request, Anthropic says
【編集部解説】
AnthropicがClaude Sonnet 4に最大100万トークンのコンテキスト(文脈)処理を開放しました。単一リクエストで約75,000行のコードや約75万語のドキュメントを一気に読み込める規模で、APIおよびAmazon Bedrock経由のPublic Betaとして段階的に展開されています。これにより、これまで分割前提だった大規模リポジトリや多数文書の横断的な関連把握が、1回の入出力で可能になります。
技術的には、長文脈での「needle in a haystack(干し草の山の中の針)」的検索・想起の正確性が論点です。Anthropicは内部評価で100%の再現性を謳いますが、これはあくまで社内テストであり、実運用におけるコード異臭検知や設計上のトレードオフ把握など、多層的な推論の持続性は現場検証が不可欠です。ただし、プロジェクト全体像を”丸ごと”見渡せること自体は、ファイル粒度の分割では失われがちだった依存関係と設計意図を保ったまま提案できる余地を広げます。
実装・料金面では、200Kトークン以下は従来の$3/MTok(入力)・$15/MTok(出力)に据え置き、200K超から$6/MTok・$22.50/MTokへ切り替わる二段制です。長文脈のβ利用は当面Tier 4およびカスタム制限の組織が対象で、プロンプトキャッシング(prompt caching(プロンプトの再利用キャッシュ))と併用することでリピート照会型ワークロードの総コストを抑制できる設計です。この「キャッシュ×長文脈」によるRAG代替のコスト・品質最適化は、法務・金融・製造のナレッジ資産を持つ企業にとって実践的な選択肢になり得ます。
市場文脈では、コード生成が企業導入の主用途として伸び、Menlo Ventures調査でAnthropicのコード生成シェアは42%、OpenAIは21%とされています。企業は価格より性能を優先し、より高性能モデルへの素早いアップグレードが常態化しています。一方で、価格攻勢を強める競合(例:GPT-5)や、プラットフォーム戦略におけるアライアンスの力学は、モデル採用の流動性を高める要因となります。
できるようになることは明確です。第一に、リポジトリ全体の設計レビュー、リファクタリング計画、仕様と実装の整合性監査を「文脈を保ったまま」一気通貫で回せます。第二に、数百ファイル規模の文書群からの合意形成資料やリスク論点の抽出など、関係性を前提とする要約・統合がしやすくなります。第三に、ツール呼び出しを跨いだエージェント運用で、長いワークフローの一貫性と再現性を保ちやすくなります。
留意すべきリスクもあります。長文脈は「見えすぎるがゆえの錯覚」を生みやすく、誤った前提の連鎖や過剰一般化が交じると、広範囲に影響する提案ミスになり得ます。加えて、過去バージョンで観測された望ましくない振る舞いの教訓から、安全性設計は今後も注視が必要です。ベータ段階では、重要判断におけるヒューマン・イン・ザ・ループを厳格に保つべきです。
規制・ガバナンス面では、長文脈化に伴い入力データの守備範囲が拡大します。権限分離、機密区分、データ最小化の実装が不十分だと、不要な個人情報・営業秘密まで取り込むリスクが増します。監査可能性(誰が・いつ・何を入力し、どの判断がなされたか)を担保するためのログ設計や、キャッシュのTTL・アクセス制御は、モデル選定と同列の経営課題です。
長期的には、RAG前処理中心の「情報を選んでから渡す」設計から、長文脈を前提に「まず全体を見せ、モデル自身に選ばせる」設計への再編が進みます。これは、情報アーキテクチャとMLOpsの分業を再定義し、エージェント編成・権限設計・コスト会計の枠組みまで影響を与えます。GeminiやOpenAIも大規模コンテキストの路線にあり、長文脈×価格×推論性能の三つ巴は当面の焦点であり続けるでしょう。
最後に、なぜ今か。モデル性能の頭打ち議論が出る中で、「入力側の律速」を外すことは実務価値に直結します。プロダクトロードマップ、設計思想、運用手順、テスト資産、ナレッジの「全体」を理解したうえで提案できるAIは、開発現場の意思決定速度と品質を底上げします。長文脈は魔法ではありませんが、現場の「分割に伴う損失」を削る現実的なテコになります。
【用語解説】
コンテキストウィンドウ(context window)
モデルが一度のリクエストで保持・参照できる入力の範囲のこと。
トークン(token)
テキストを分割した最小単位で、課金やモデルの処理量の基準となる。
needle in a haystack(干し草の山の中の針)
大量テキスト中の特定情報を探索する内部評価手法の通称。
Public Beta(公開ベータ)
一般開放された試験提供段階で、正式版前の段階を指す。
プロンプトキャッシング(prompt caching)
繰り返し使う大規模プロンプトをキャッシュして遅延とコストを削減する仕組み。
RAG(Retrieval-Augmented Generation)
検索・取得結果を補助情報として生成に用いる方式。
リポジトリ横断コード解析
リポジトリ全体を読み込み、依存関係や設計をまたいで解析・提案すること。
コンテキスト対応エージェント
長いワークフローや多数のツール呼び出しにわたり文脈を保持するAIエージェント。
【参考リンク】
Anthropic(外部)
人工知能モデルClaudeを提供する企業で、Sonnet 4の1Mトークン文脈を発表している。
Claude Sonnet 4: 1Mトークン対応発表(外部)
Sonnet 4の1Mトークン対応、ユースケース、価格調整、提供範囲を案内する発表ページである。
Anthropic API Pricing(外部)
Sonnet 4の長文脈価格やティア条件、バッチ割引、キャッシュ適用などの詳細を示す。
Amazon Bedrock(外部)
複数基盤モデルを提供するAWSの生成AIサービスで、Claudeの提供も含む。
Google Cloud Vertex AI(外部)
Google CloudのAIプラットフォームで、基盤モデルの提供と統合機能を持つ。
【参考動画】
【参考記事】
Claude Sonnet 4 now supports 1M tokens of context(外部)
Sonnet 4が最大1Mトークンの文脈に対応し、リポジトリ全体の解析、文書群統合、コンテキスト対応エージェントなどのユースケースが拡張された。
Anthropic’s Claude AI model can now handle longer prompts(外部)
Sonnet 4が1Mトークンに対応し、約750,000語または75,000行規模の入力が可能になった。
Menlo Ventures – 2025 Mid-Year LLM Market Update(外部)
企業LLM市場のシェア変動、API支出の倍増、コード生成の台頭、Anthropicのコード生成シェア42%などを提示。
Techmeme summary: Anthropic updates Claude Sonnet 4(外部)
1Mトークンの文脈対応、約750K語/75K行、5倍拡張という要点を集約し、同日の報道の中心情報を短く示す。
Simon Willison: Claude Sonnet 4 now supports 1M tokens of context(外部)200Kと1Mでの二段価格、βヘッダー指定、Tier 4制限など、実装上の具体的留意点を補足し、他社(Gemini)の価格比較も紹介。
【編集部後記】
みなさんは、開発しているサービスやプロジェクトの全体像を、AIが一度に理解して提案してくれるとしたら、どんな活用を思い描きますか。75,000行のコードベースを分割せずに扱えることは、単なる効率化を超えた可能性を秘めています。
これまで、大規模なシステムの改善提案を得るためには、開発者が手作業でコードを分割し、重要な文脈を失うリスクを抱えながら作業していました。しかし今回のClaude Sonnet 4の長文脈対応により、プロジェクト全体の設計思想や依存関係を保ったまま、AIからの提案を受けられるようになります。
もちろん、200Kトークン超で$6/$22.50という価格設定は決して安くありません。しかし、分割作業に費やしていた時間コストや、文脈を失うことで生じる品質リスクを考慮すれば、多くの企業にとって合理的な投資と言えるでしょう。
この技術がもし皆さんの職場や個人プロジェクトに導入されたら、どんな変化が起こるのか。コードレビューの質は向上するのか、設計判断のスピードは上がるのか。そして何より、開発者の創造性がより高い領域に向かうのか。ぜひ想像しながら、この技術の可能性について考えてみてください。